WProofreader v6.11.0 simplifies self-hosted deployment by removing domain name requirements, introduces new JS core options for scaled layouts and RTL badge control, changes the default English check kit to ai_lt_hs1 for cloud users, expands dictionaries with 9,700+ new entries, updates the grammar engine with major Catalan improvements, and patches a security vulnerability.
Check the TL;DR below.
📝 TL;DR
- [Cloud] Default text-checking configuration for English changed to
ai_lt_hs1. Combines the AI proofreading engine with the algorithmic grammar and spelling engines for improved accuracy - Self-hosted installation no longer requires a domain name — simplified setup for Docker, Windows, and Linux
- New enableScale and disableBadgeRTLMirroring options in WProofreader JS core
- Expanded dictionaries with 9,700+ new entries across English, German, Spanish, Ukrainian, and Russian
- Extended German dictionary with 13,550+ compound word forms for feminine nouns with Fuge-s
- Updated third-party grammar engine with major Catalan improvements and rule refinements for German, Spanish, Portuguese, Ukrainian, and English
- Custom user dictionaries now accept words that already exist in core spelling dictionaries
- Security fix. Updated jackson-core to address GHSA-72hv-8253-57qq
🛠 Enhancements
WProofreader JS core (v3.39.6037)
- Introduced a new enableScale option. Enables support for CSS scale transformations applied to parent elements. When enabled, WProofreader detects the scale value of the parent element and adjusts UI elements accordingly, ensuring that highlighting and interface elements remain correctly aligned when the surrounding content is scaled. Disabled by default.
- Introduced a new disableBadgeRTLMirroring option. Disables automatic badge position mirroring for right-to-left (RTL) languages such as Arabic. When enabled, the badge keeps its configured position instead of being automatically mirrored according to text direction. Manual badge positioning options remain unchanged. Disabled by default.
Deployment
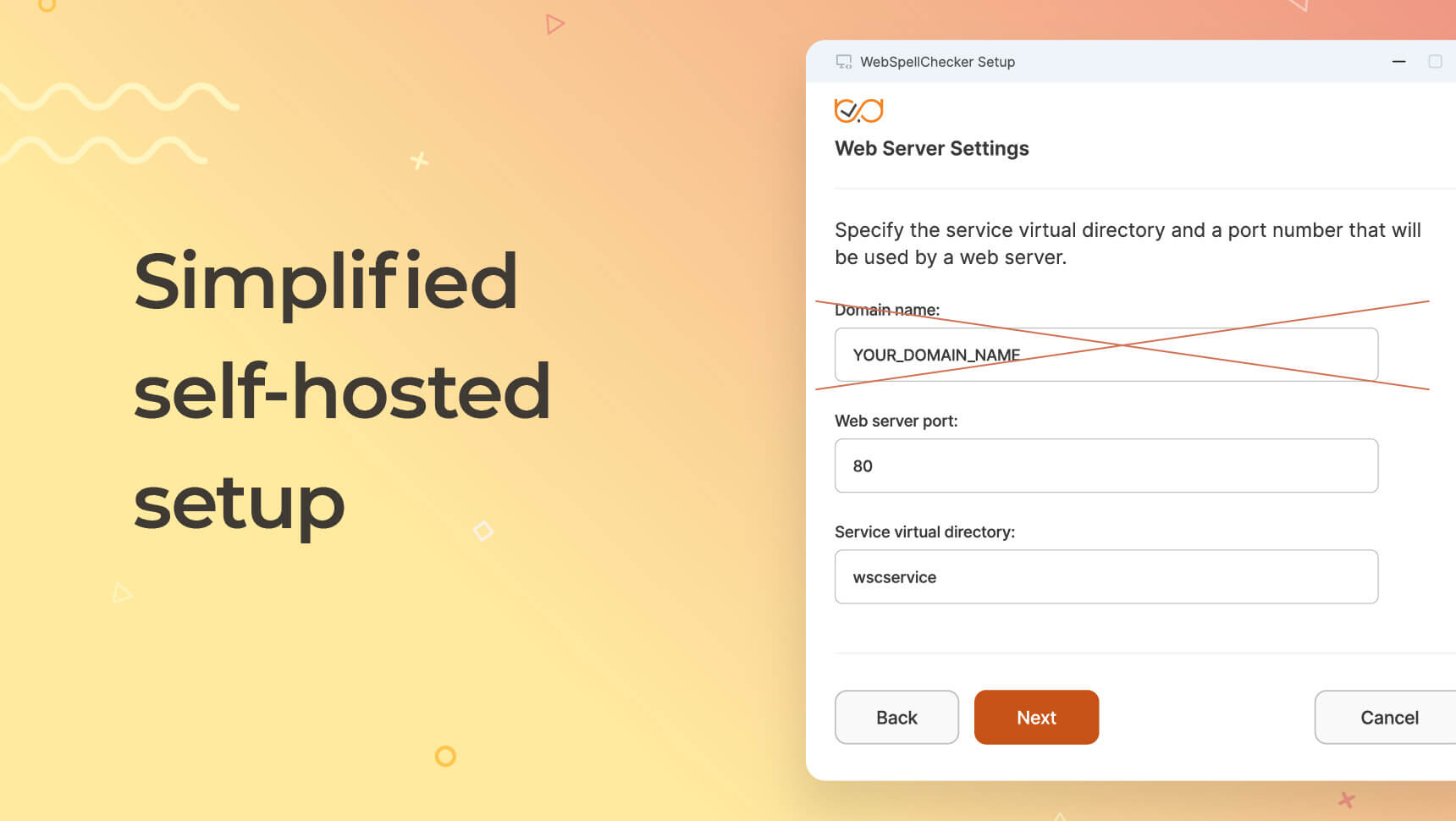
- Removed the requirement to specify a domain name during installation for the self-hosted version. This simplifies initial setup across Docker, Windows, and Linux environments:
- Docker. Removed the
WPR_DOMAIN_NAMEparameter. Added support for running the container from the root path (/) viaWPR_VIRTUAL_DIR. Learn more about the Docker configuration. - Helm chart. Updated to v1.3.1. Allowed setting empty
virtualDir(/), removedWPR_DOMAIN_NAMEfrom theextraEnvexample, and updatedappVersionto6.11.0.0. Learn more about the Helm chart. - Windows and Linux installers. The web server now listens on any domain by default, removing a common setup step.
- Docker. Removed the
Application server
- [Cloud] Changed the default text-checking configuration for English to
ai_lt_hs1. This configuration combines the AI proofreading engine with the algorithmic grammar engine (LanguageTool) and the algorithmic spelling engine (Hunspell) with spelling suggestions for improved accuracy. Previously, the default configuration (ai_lt_hs0) included Hunspell for error detection but without spelling suggestions. If needed, the previous behavior can be restored by setting the checkKit option toai_lt_hs0. - Improved error logging. The application server now provides more detailed messages when Hunspell dictionaries fail to load, when an AI language model is missing, or when an n-gram model isn’t found. This makes it easier to diagnose configuration issues during deployment.
- Added the ability to configure the maximum sequence length in the AI model configuration.
- Improved file path handling across the application server to use absolute paths instead of searching in the current working directory. This resolves issues when the application server runs as a systemd service on Linux.
⚙️ Grammar engine
- Updated the third-party grammar engine with improvements across multiple languages.
- Catalan. Major update including a new proper noun recognition system that reduces false spelling errors for names seen earlier in text, improved verb replacement suggestions with better pronoun handling, new multitoken speller dictionary for better multi-word spelling suggestions, added support for causal constructions (al no + infinitive → com que…), updated Catalan POS dictionary to v3.3, expanded spelling and multiword dictionaries, improved sentence segmentation with the fund. abbreviation for Catalan and Spanish, and various disambiguation rule refinements.
- German. Improved grammar rules for the nach zu geben construction and added rules for handling German number formatting with dot separators (e.g., 100.000).
- Spanish. Added an antipattern for volares as an adjective to prevent incorrect subjunctive suggestions.
- Portuguese. Significant disambiguation improvements including better handling of pela/pelas as prepositions, refined verb-to-noun/adjective disambiguation, new context-based tagging for semantic categories, enabled the redundant comma after dash rule, expanded confused words rules, added antipatterns for K2 mountain and Samsung Galaxy references, and various style rule refinements for Brazilian Portuguese.
- Ukrainian. Updated morphological dictionary to v6.7.5, expanded abbreviation handling (e.g., крим, пом, суч), improved word tokenizer patterns, added numerous soft replacement suggestions, expanded derivation rules, and improved disambiguation for vocative case and other grammar constructs.
- English. Added misgendered, misgender, misgenders, misgendering to the spelling dictionary and improved prefix handling in spelling suggestions.
📚 Spelling engine
- Expanded dictionaries with 9,700+ new entries across English, German, Spanish, Ukrainian, and Russian, covering abbreviations, affixes, biology, chemistry, common terms, dialectal variations, medical, military, neologisms, proper names, technology, and more.
- Extended the German dictionary with 13,550+ Fuge-s compound word forms for feminine nouns combined with a hyphen (e.g., Präventions-).
- Enriched shared cross-language dictionaries with 125 new common proper names and abbreviations.
- Added new Russian language resources.
- Refined word lists by removing 500+ invalid or incorrect entries across English, Spanish, and German, targeting nonexistent words, incorrect medical terms, invalid abbreviation and capitalized forms, and non-dialectal entries.
- Optimized split patterns with 20 new rules for English and Spanish covering reflexive verbs, common words, pronouns, and adverbs to prevent incorrect word splitting. Improved suggestion quality by excluding offensive terms in certain contexts and removing invalid suggestions across multiple categories.
- Enhanced medical terminology for English and Spanish with 255+ new entries covering Latin terms, medical adjectives, disease names, and abbreviations. Refined medical word lists by removing 230+ invalid entries targeting incorrect words, abbreviation forms, and capitalized forms.
- Added support for two types of apostrophes in Catalan (U+2019 and U+0027).
💡 Autocorrect
- Refined prioritization rules for common English and Spanish misspellings. Enhanced prioritization in the shared cross-language dictionary.
- Improved correction logic by removing invalid English and Spanish autocorrect entries targeting incorrect suggestions.
📝 Style
- Updated style rules for English with new rules addressing slurs and race and ethnicity insults.
📖 Custom dictionary
- Starting with v6.11.0, words that exist in core spelling dictionaries can be added to custom user dictionaries as well.
🛡 Security
- Updated the vulnerable jackson-core library (used by the grammar engine) to version 2.18.6 to address GHSA-72hv-8253-57qq (number length constraint bypass in async JSON parser, which could lead to a potential denial of service condition).
🐞 Bug fixes
- WProofreader JS core: Highlighted suggestions are shifted when the Zoom plugin is used in CKEditor
- WProofreader JS core: Inconsistent behavior of the keyboard navigation in the AI writing assistant dialog in mixed left-to-right/right-to-left environments
- Spelling engine: Words spelled using typographic apostrophes aren’t recognized as correct in Catalan
- Spelling engine: Split rules containing numbers aren’t allowed
- Application server: Allowed rules functionality doesn’t work as expected
- Application server: Hunspell fails if n-gram model isn’t found
- Style guide: Core style guide rules can’t be read
- Style guide: Relative paths are used for style guide files