WProofreader v6.11.0 simplifie le déploiement en auto-hébergement en supprimant les exigences relatives au nom de domaine, introduit de nouvelles options JS de base pour les mises en page adaptatives et le contrôle des badges RTL, et remplace le kit de vérification par défaut en anglais par ai_lt_hs1, destiné aux utilisateurs du cloud, enrichit les dictionnaires de plus de 9 700 nouvelles entrées, met à jour le moteur grammatical avec des améliorations majeures pour le catalan et corrige une faille de sécurité.
Consultez le résumé ci-dessous.
📝 En bref
- [Cloud] La configuration par défaut de la vérification du texte en anglais a été modifiée pour devenir
ai_lt_hs1. Associe le moteur de relecture basé sur l'IA aux moteurs algorithmiques de grammaire et d'orthographe pour une précision accrue - L'installation en auto-hébergement ne nécessite plus de nom de domaine — configuration simplifiée pour Docker, Windows et Linux
- Nouvelles options « enableScale » et « disableBadgeRTLMirroring » dans le cœur de WProofreader JS
- Des dictionnaires enrichis comprenant plus de 9 700 nouvelles entrées en anglais, allemand, espagnol, ukrainien et russe
- Dictionnaire allemand élargi comprenant plus de 13 550 formes de mots composés pour les noms féminins se terminant par « Fuge-s »
- Mise à jour du moteur de grammaire tiers, avec des améliorations majeures pour le catalan et des affinements des règles pour l'allemand, l'espagnol, le portugais, l'ukrainien et l'anglais
- Les dictionnaires personnalisés acceptent désormais les mots qui figurent déjà dans les dictionnaires d'orthographe par défaut.
- Correctif de sécurité. Mise à jour de jackson-core pour corriger la vulnérabilité GHSA-72hv-8253-57qq
🛠 Améliorations
Noyau WProofreader JS (v3.39.6037)
- Ajout d'une nouvelle option « enableScale ». Elle active la prise en charge des transformations d'échelle CSS appliquées aux éléments parents. Lorsqu'elle est activée, WProofreader détecte la valeur d'échelle de l'élément parent et ajuste les éléments de l'interface utilisateur en conséquence, garantissant ainsi que les surlignages et les éléments d'interface restent correctement alignés lorsque le contenu environnant est redimensionné. Désactivée par défaut.
- Ajout d'une nouvelle option « disableBadgeRTLMirroring ». Elle désactive la mise en miroir automatique de la position des badges pour les langues s'écrivant de droite à gauche (RTL), telles que l'arabe. Lorsqu'elle est activée, le badge conserve la position qui lui a été attribuée au lieu d'être automatiquement mis en miroir en fonction du sens d'écriture. Les options de positionnement manuel des badges restent inchangées. Cette option est désactivée par défaut.
Déploiement
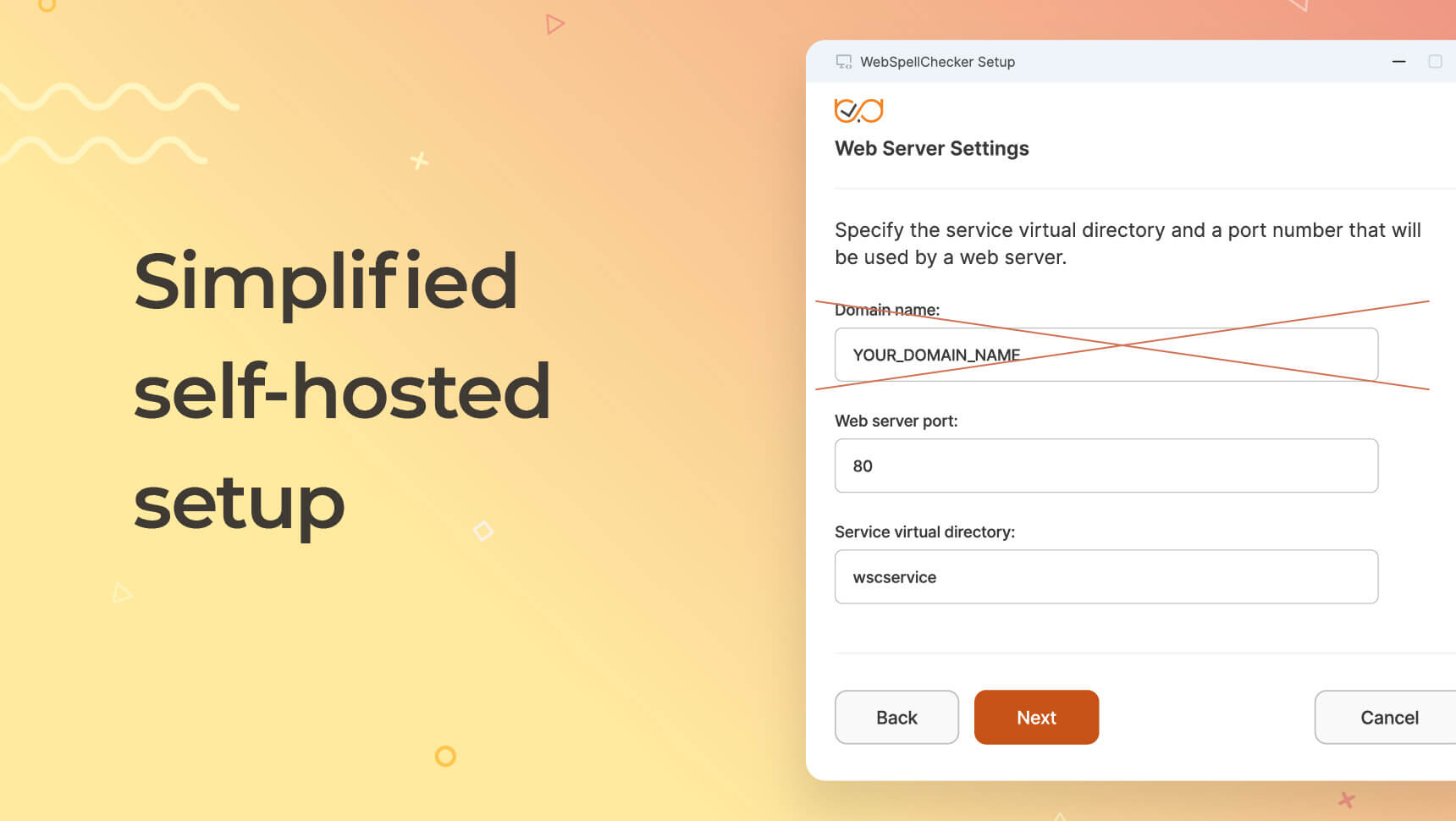
- La nécessité de spécifier un nom de domaine lors de l'installation de la version auto-hébergée a été supprimée. Cela simplifie la configuration initiale dans les environnements Docker, Windows et Linux :
- Docker. Suppression du
WPR_DOMAIN_NAMEparamètre. Ajout de la prise en charge de l'exécution du conteneur à partir du chemin racine (/) viaWPR_VIRTUAL_DIR. En savoir plus sur le Configuration de Docker. - Tableau Helm. Mise à jour vers la version 1.3.1. Possibilité de définir une valeur vide
virtualDir(/), suppriméWPR_DOMAIN_NAMEtiré de laextraEnvexemple, et mis à jourappVersionà6.11.0.0. En savoir plus sur le Carte de navigation. - Programmes d'installation pour Windows et Linux. Le serveur web écoute désormais sur n'importe quel domaine par défaut, ce qui supprime une étape courante de la configuration.
- Docker. Suppression du
Serveur d'applications
- [Cloud] Modification de la configuration par défaut de la vérification orthographique pour l'anglais afin qu'elle soit
ai_lt_hs1. Cette configuration associe le moteur de relecture basé sur l'IA au moteur grammatical algorithmique (LanguageTool) et au moteur orthographique algorithmique (Hunspell), avec des suggestions orthographiques pour une précision accrue. Auparavant, la configuration par défaut (ai_lt_hs0) intégrait Hunspell pour la détection des erreurs, mais sans propositions orthographiques. Si nécessaire, il est possible de rétablir le comportement précédent en configurant le checkKit option pourai_lt_hs0. - Amélioration de la journalisation des erreurs. Le serveur d'applications affiche désormais des messages plus détaillés lorsque le chargement des dictionnaires Hunspell échoue, lorsqu'un modèle linguistique basé sur l'IA est manquant ou lorsqu'un modèle n-gram n'est pas trouvé. Cela facilite le diagnostic des problèmes de configuration lors du déploiement.
- Ajout de la possibilité de configurer la longueur maximale des séquences dans les paramètres du modèle d'IA.
- Amélioration de la gestion des chemins d'accès aux fichiers sur l'ensemble du serveur d'applications afin d'utiliser des chemins absolus plutôt que d'effectuer des recherches dans le répertoire de travail actuel. Cela permet de résoudre les problèmes rencontrés lorsque le serveur d'applications s'exécute en tant que service systemd sous Linux.
⚙️ Moteur grammatical
- Mise à jour du moteur de grammaire tiers avec des améliorations dans plusieurs langues.
- Catalan. Mise à jour majeure comprenant un nouveau système de reconnaissance des noms propres qui réduit les fausses erreurs d'orthographe pour les noms déjà apparus dans le texte, des suggestions améliorées de remplacement de verbes avec une meilleure gestion des pronoms, un nouveau dictionnaire orthographique multitoken pour de meilleures suggestions d'orthographe des expressions à plusieurs mots, la prise en charge des constructions causales (al no + infinitif → com que…), la mise à jour du dictionnaire POS catalan vers la version 3.3, l'élargissement des dictionnaires orthographiques et des expressions à plusieurs mots, l'amélioration de la segmentation des phrases grâce à l'abréviation « fund. abréviation pour le catalan et l’espagnol, ainsi que diverses améliorations des règles de désambiguïsation.
- Allemand. Amélioration des règles grammaticales relatives à la construction « nach zu geben » et ajout de règles pour la gestion du formatage des nombres en allemand avec des séparateurs sous forme de points (par exemple, 100.000).
- Espagnol. Ajout d'un anti-modèle pour « volares » utilisé comme adjectif afin d'éviter les suggestions erronées au subjonctif.
- Portugais. Améliorations significatives en matière de désambiguïsation, notamment une meilleure prise en charge des mots « pela » et « pelas » en tant que prépositions, un affinement de la désambiguïsation entre verbes, noms et adjectifs, un nouveau marquage basé sur le contexte pour les catégories sémantiques, l'activation de la règle relative à la virgule redondante après un tiret, l'élargissement des règles concernant les mots pouvant prêter à confusion, l'ajout d'anti-modèles pour les références au mont K2 et au Samsung Galaxy, ainsi que diverses améliorations des règles de style pour le portugais brésilien.
- Ukrainien. Mise à jour du dictionnaire morphologique vers la version 6.7.5, extension de la prise en charge des abréviations (par exemple : крим, пом, суч), amélioration des modèles du segmentateur de mots, ajout de nombreuses suggestions de remplacement souple, extension des règles de dérivation et amélioration de la désambiguïsation pour le cas vocatif et d'autres constructions grammaticales.
- Anglais. Ajout des termes « misgendered », « misgender », « misgenders » et « misgendering » au dictionnaire orthographique et amélioration de la gestion des préfixes dans les suggestions orthographiques.
📚 Moteur de vérification orthographique
- Des dictionnaires enrichis comprenant plus de 9 700 nouvelles entrées en anglais, allemand, espagnol, ukrainien et russe, couvrant les abréviations, les affixes, la biologie, la chimie, les termes courants, les variations dialectales, le domaine médical, le domaine militaire, les néologismes, les noms propres, la technologie, et bien plus encore.
- Le dictionnaire allemand a été enrichi de plus de 13 550 formes de mots composés se terminant par «-Fuge-s » pour les noms féminins associés à un trait d'union (par exemple, « Präventions- »).
- Enrichissement des dictionnaires multilingues communs avec 125 nouveaux noms propres et abréviations courants.
- Ajout de nouvelles ressources en russe.
- Nous avons affiné les listes de mots en supprimant plus de 500 entrées invalides ou incorrectes en anglais, en espagnol et en allemand, en ciblant notamment les mots inexistants, les termes médicaux erronés, les abréviations et les formes en majuscules non valides, ainsi que les entrées non dialectales.
- Modèles de segmentation optimisés grâce à 20 nouvelles règles pour l'anglais et l'espagnol, couvrant les verbes pronominaux, les mots courants, les pronoms et les adverbes, afin d'éviter toute segmentation incorrecte des mots. Amélioration de la qualité des suggestions grâce à l'exclusion des termes offensants dans certains contextes et à la suppression des suggestions non valides dans plusieurs catégories.
- Enrichissement de la terminologie médicale en anglais et en espagnol avec plus de 255 nouvelles entrées couvrant les termes latins, les adjectifs médicaux, les noms de maladies et les abréviations. Affinement des listes de termes médicaux grâce à la suppression de plus de 230 entrées invalides, notamment des mots incorrects, des formes d'abréviations et des formes en majuscules.
- Ajout de la prise en charge de deux types d'apostrophes en catalan (U+2019 et U+0027).
💡 Correction automatique
- Règles de hiérarchisation affinées pour les fautes d'orthographe courantes en anglais et en espagnol. Hiérarchisation améliorée dans le dictionnaire multilingue partagé.
- Amélioration de la logique de correction grâce à la suppression des entrées de correction automatique erronées en anglais et en espagnol, afin d'éviter les suggestions incorrectes.
📝 Style
- Mise à jour des règles stylistiques pour l'anglais, avec l'ajout de nouvelles dispositions concernant les propos injurieux et les insultes à caractère racial ou ethnique.
📖 Dictionnaire personnalisé
- À partir de la version 6.11.0, les mots figurant dans les dictionnaires d'orthographe par défaut peuvent également être ajoutés aux dictionnaires personnalisés des utilisateurs.
🛡 Sécurité
- La bibliothèque « jackson-core » (utilisée par le moteur de grammaire), qui présentait une vulnérabilité, a été mise à jour vers la version 2.18.6 afin de corriger la faille GHSA-72hv-8253-57qq (contournement de la contrainte de longueur des nombres dans l'analyseur JSON asynchrone, pouvant entraîner une situation potentielle de déni de service).
🐞 Corrections de bugs
- Noyau WProofreader JS : les suggestions mises en évidence sont décalées lorsque le plugin Zoom est utilisé dans CKEditor
- Noyau de WProofreader JS : comportement irrégulier de la navigation au clavier dans la boîte de dialogue de l'assistant de rédaction IA dans des environnements mixtes (de gauche à droite/de droite à gauche)
- Moteur de vérification orthographique : les mots comportant des apostrophes typographiques ne sont pas reconnus comme corrects en catalan.
- Moteur d'orthographe : les règles de division contenant des chiffres ne sont pas autorisées
- Serveur d'applications : la fonctionnalité des règles autorisées ne fonctionne pas comme prévu
- Serveur d'applications : Hunspell échoue si le modèle n-gram n'est pas trouvé
- Guide de style : les règles fondamentales du guide de style ne sont pas consultables
- Guide de style : les chemins d'accès relatifs sont utilisés pour les fichiers du guide de style