WProofreader v6.11.0 vereinfacht die selbst gehostete Bereitstellung, indem es die Anforderungen an den Domainnamen aufhebt, führt neue JS-Kernoptionen für skalierbare Layouts und die Steuerung von RTL-Badges ein und ändert das standardmäßige englische Prüfpaket auf ai_lt_hs1 für Cloud-Nutzer erweitert die Wörterbücher um mehr als 9.700 neue Einträge, aktualisiert die Grammatik-Engine mit wesentlichen Verbesserungen für Katalanisch und behebt eine Sicherheitslücke.
Lies dir die Zusammenfassung unten durch.
📝 Kurzfassung
- [Cloud] Die Standardkonfiguration für die Textprüfung im Englischen wurde geändert auf
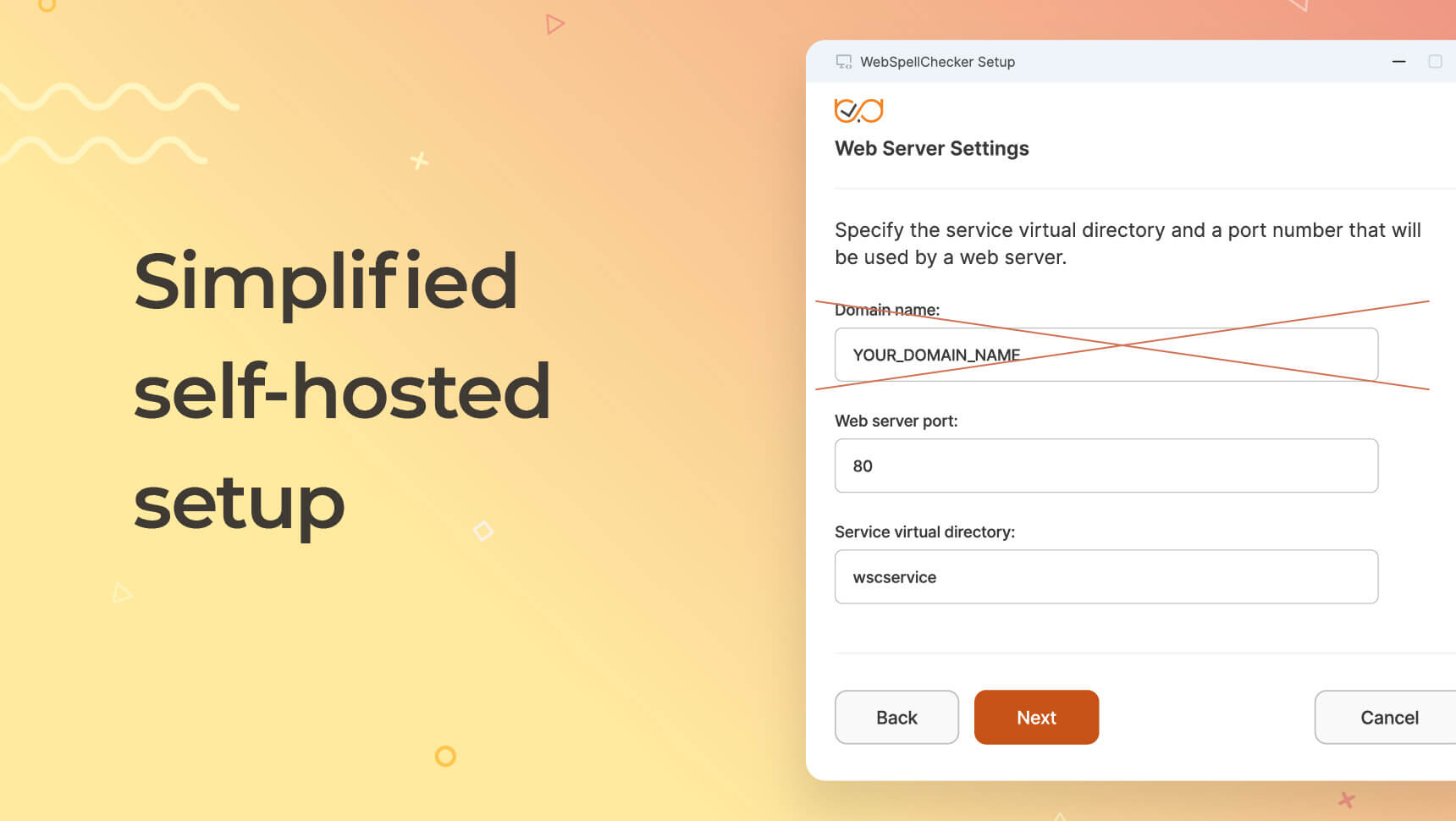
ai_lt_hs1. Kombiniert die KI-Korrektur-Engine mit den algorithmischen Grammatik- und Rechtschreib-Engines für eine höhere Genauigkeit - Für die selbst gehostete Installation ist kein Domainname mehr erforderlich – vereinfachte Einrichtung für Docker, Windows und Linux
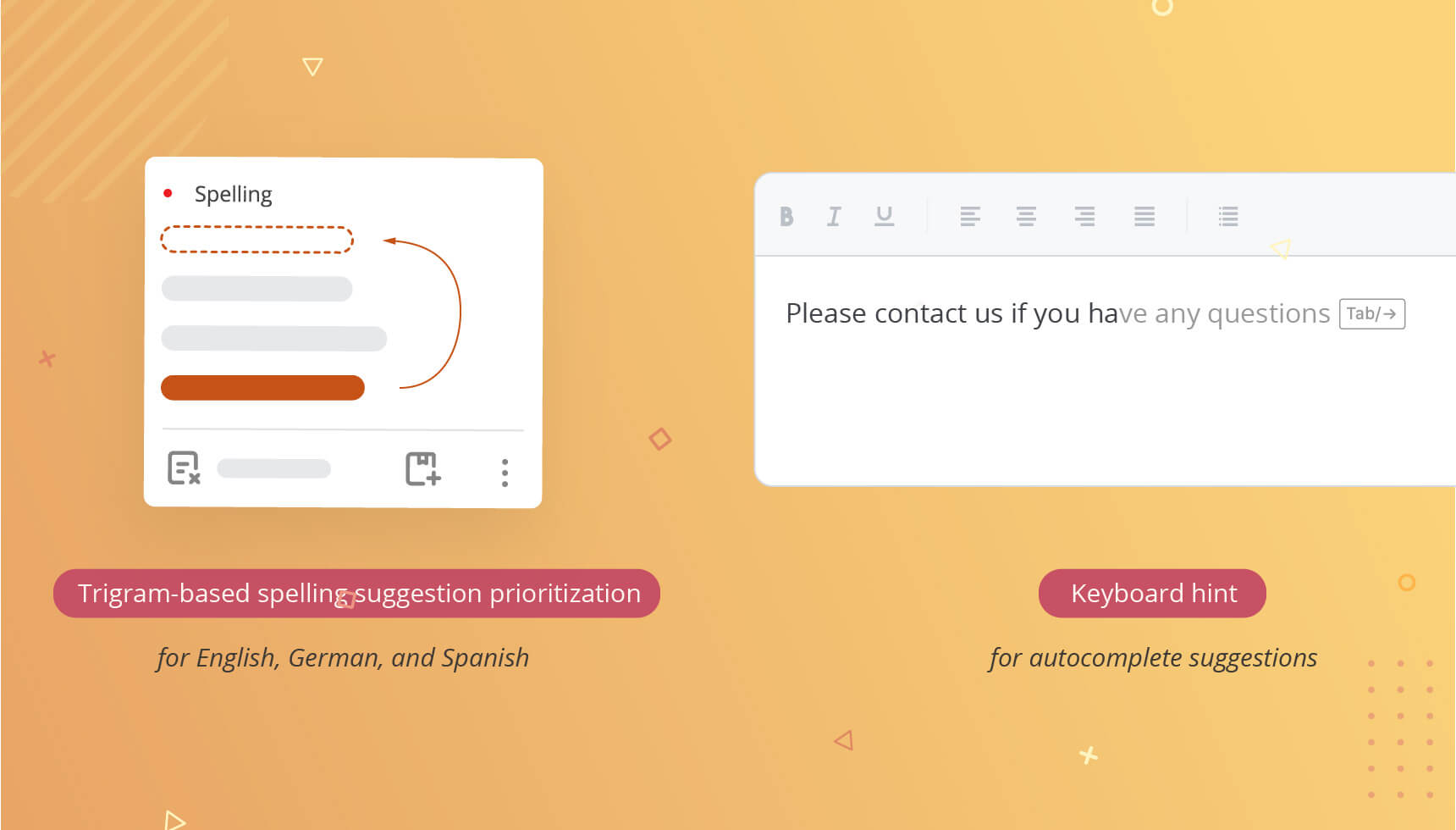
- Neue Optionen „enableScale“ und „disableBadgeRTLMirroring“ im WProofreader-JS-Kern
- Erweiterte Wörterbücher mit über 9.700 neuen Einträgen in Englisch, Deutsch, Spanisch, Ukrainisch und Russisch
- Erweitertes Deutsch-Wörterbuch mit über 13.550 zusammengesetzten Wortformen für weibliche Substantive mit „Fuge-s“
- Aktualisierte Grammatik-Engine eines Drittanbieters mit wesentlichen Verbesserungen für Katalanisch sowie Regelverfeinerungen für Deutsch, Spanisch, Portugiesisch, Ukrainisch und Englisch
- Benutzerdefinierte Wörterbücher akzeptieren nun auch Wörter, die bereits in den Standard-Rechtschreibwörterbüchern enthalten sind.
- Sicherheitskorrektur. „jackson-core“ wurde aktualisiert, um das Problem GHSA-72hv-8253-57qq zu beheben.
🛠 Verbesserungen
WProofreader JS-Kern (v3.39.6037)
- Es wurde eine neue Option „enableScale“ eingeführt. Sie aktiviert die Unterstützung für CSS-Skalierungstransformationen, die auf übergeordnete Elemente angewendet werden. Wenn diese Option aktiviert ist, erkennt WProofreader den Skalierungswert des übergeordneten Elements und passt die UI-Elemente entsprechend an, sodass Hervorhebungen und Oberflächenelemente auch bei einer Skalierung des umgebenden Inhalts korrekt ausgerichtet bleiben. Standardmäßig deaktiviert.
- Es wurde eine neue Option „disableBadgeRTLMirroring“ eingeführt. Diese deaktiviert die automatische Spiegelung der Badge-Position für Sprachen mit Rechts-nach-Links-Schreibrichtung (RTL) wie beispielsweise Arabisch. Bei Aktivierung behält das Badge seine konfigurierte Position bei, anstatt automatisch entsprechend der Textrichtung gespiegelt zu werden. Die Optionen zur manuellen Positionierung des Badges bleiben unverändert. Standardmäßig deaktiviert.
Bereitstellung
- Die Anforderung, bei der Installation der selbst gehosteten Version einen Domänennamen anzugeben, wurde aufgehoben. Dies vereinfacht die Ersteinrichtung in Docker-, Windows- und Linux-Umgebungen:
- Docker. Das
WPR_DOMAIN_NAMEParameter. Unterstützung für die Ausführung des Containers aus dem Stammverzeichnis hinzugefügt (/) überWPR_VIRTUAL_DIR. Erfahren Sie mehr über die Docker-Konfiguration. - Helm-Diagramm. Aktualisiert auf Version 1.3.1. Leere Werte können nun festgelegt werden.
virtualDir(/), entferntWPR_DOMAIN_NAMEaus demextraEnvBeispiel und aktualisiertappVersionzu6.11.0.0. Erfahren Sie mehr über die Kompasskarte. - Installationsprogramme für Windows und Linux. Der Webserver lauscht nun standardmäßig auf jeder beliebigen Domain, wodurch ein üblicher Einrichtungsschritt entfällt.
- Docker. Das
Anwendungsserver
- [Cloud] Die Standardkonfiguration für die Textprüfung für Englisch wurde geändert auf
ai_lt_hs1. Diese Konfiguration kombiniert die KI-Korrektur-Engine mit der algorithmischen Grammatik-Engine (LanguageTool) und der algorithmischen Rechtschreib-Engine (Hunspell) mit Rechtschreibvorschlägen für eine höhere Genauigkeit. Bisher war die Standardkonfiguration (ai_lt_hs0) enthielt Hunspell zur Fehlererkennung, jedoch ohne Rechtschreibvorschläge. Bei Bedarf lässt sich das bisherige Verhalten wiederherstellen, indem man die checkKit Option fürai_lt_hs0. - Verbesserte Fehlerprotokollierung. Der Anwendungsserver gibt nun detailliertere Meldungen aus, wenn Hunspell-Wörterbücher nicht geladen werden können, wenn ein KI-Sprachmodell fehlt oder wenn ein N-Gram-Modell nicht gefunden wird. Dies erleichtert die Diagnose von Konfigurationsproblemen während der Bereitstellung.
- Es wurde die Möglichkeit hinzugefügt, die maximale Sequenzlänge in der Konfiguration des KI-Modells festzulegen.
- Die Verarbeitung von Dateipfaden auf dem Anwendungsserver wurde verbessert, sodass nun absolute Pfade verwendet werden, anstatt im aktuellen Arbeitsverzeichnis zu suchen. Dadurch werden Probleme behoben, die auftreten, wenn der Anwendungsserver unter Linux als systemd-Dienst ausgeführt wird.
⚙️ Grammatik-Engine
- Die Grammatik-Engine eines Drittanbieters wurde aktualisiert und um Verbesserungen für mehrere Sprachen erweitert.
- Katalanisch. Umfangreiches Update mit einem neuen System zur Erkennung von Eigennamen, das falsche Rechtschreibfehler bei bereits im Text vorkommenden Namen reduziert, verbesserten Vorschlägen zum Ersetzen von Verben mit optimierter Behandlung von Pronomen, einem neuen Multitoken-Rechtschreibwörterbuch für bessere Rechtschreibvorschläge bei Mehrwortausdrücken, zusätzlicher Unterstützung für Kausalkonstruktionen (al no + Infinitiv → com que…), einem auf Version 3.3 aktualisierten katalanischen POS-Wörterbuch, erweiterten Rechtschreib- und Mehrwortwörterbüchern, verbesserter Satzsegmentierung mit der Abkürzung „fund“. Abkürzung für Katalanisch und Spanisch sowie verschiedene Verfeinerungen der Regeln zur Begriffsklärung.
- Deutsch. Die Grammatikregeln für die Konstruktion „nach … zu geben“ wurden verbessert und es wurden Regeln für die Verarbeitung der deutschen Zahlenformatierung mit Punkttrennzeichen (z. B. 100.000) hinzugefügt.
- Spanisch. Es wurde ein Antipattern für „volares“ als Adjektiv hinzugefügt, um falsche Vorschläge im Konjunktiv zu vermeiden.
- Portugiesisch. Wesentliche Verbesserungen bei der Begriffsklärung, darunter eine bessere Behandlung von „pela/pelas“ als Präpositionen, eine verfeinerte Begriffsklärung bei der Umwandlung von Verben in Substantive bzw. Adjektive, eine neue kontextbasierte Kennzeichnung für semantische Kategorien, die Aktivierung der Regel für das redundante Komma nach dem Bindestrich, erweiterte Regeln für leicht zu verwechselnde Wörter, das Hinzufügen von Antimustern für Verweise auf den Berg K2 und das Samsung Galaxy sowie verschiedene Verfeinerungen der Stilregeln für brasilianisches Portugiesisch.
- Ukrainisch. Das morphologische Wörterbuch wurde auf Version 6.7.5 aktualisiert, die Verarbeitung von Abkürzungen wurde erweitert (z. B. крим, пом, суч), die Muster des Wort-Tokenizers wurden verbessert, zahlreiche Vorschläge für weiche Ersetzungen wurden hinzugefügt, die Ableitungsregeln wurden erweitert und die Disambiguierung für den Vokativ sowie andere grammatikalische Konstrukte wurde verbessert.
- Englisch. Die Begriffe „misgendered“, „misgender“, „misgenders“ und „misgendering“ wurden in das Rechtschreibwörterbuch aufgenommen, und die Behandlung von Präfixen in den Rechtschreibvorschlägen wurde verbessert.
📚 Rechtschreibprüfung
- Erweiterte Wörterbücher mit über 9.700 neuen Einträgen in Englisch, Deutsch, Spanisch, Ukrainisch und Russisch, die Abkürzungen, Affixe, Biologie, Chemie, gängige Begriffe, dialektale Varianten, Medizin, Militär, Neologismen, Eigennamen, Technik und vieles mehr abdecken.
- Das deutsche Wörterbuch wurde um mehr als 13.550 „Fuge-s“-Zusammensetzungen für weibliche Substantive erweitert, die mit einem Bindestrich kombiniert werden (z. B. „Präventions-“).
- Die gemeinsamen sprachübergreifenden Wörterbücher wurden um 125 neue gebräuchliche Eigennamen und Abkürzungen erweitert.
- Es wurden neue Ressourcen in russischer Sprache hinzugefügt.
- Die Wortlisten wurden verfeinert, indem über 500 ungültige oder fehlerhafte Einträge in Englisch, Spanisch und Deutsch entfernt wurden. Dabei wurden nicht existierende Wörter, falsche medizinische Begriffe, ungültige Abkürzungen und großgeschriebene Formen sowie nicht dialektale Einträge aussortiert.
- Optimierte Worttrennmuster mit 20 neuen Regeln für Englisch und Spanisch, die reflexive Verben, gebräuchliche Wörter, Pronomen und Adverbien abdecken, um eine fehlerhafte Worttrennung zu verhindern. Die Qualität der Vorschläge wurde verbessert, indem anstößige Begriffe in bestimmten Kontexten ausgeschlossen und ungültige Vorschläge über mehrere Kategorien hinweg entfernt wurden.
- Erweiterte medizinische Terminologie für Englisch und Spanisch mit über 255 neuen Einträgen, darunter lateinische Begriffe, medizinische Adjektive, Krankheitsnamen und Abkürzungen. Verfeinerte medizinische Wortlisten durch das Entfernen von über 230 ungültigen Einträgen, darunter falsche Wörter, Abkürzungsformen und großgeschriebene Formen.
- Es wurde die Unterstützung für zwei Arten von Apostrophen im Katalanischen (U+2019 und U+0027) hinzugefügt.
💡 Autokorrektur
- Verfeinerte Priorisierungsregeln für häufige Rechtschreibfehler im Englischen und Spanischen. Verbesserte Priorisierung im gemeinsamen sprachübergreifenden Wörterbuch.
- Die Korrekturlogik wurde verbessert, indem ungültige Einträge der Autokorrektur für Englisch und Spanisch entfernt wurden, die auf falsche Vorschläge abzielten.
📝 Stil
- Aktualisierte Stilrichtlinien für Englisch mit neuen Regeln zu abwertenden Bezeichnungen sowie Beleidigungen in Bezug auf Rasse und ethnische Zugehörigkeit.
📖 Benutzerdefiniertes Wörterbuch
- Ab Version 6.11.0 können Wörter, die in den Standard-Rechtschreibwörterbüchern enthalten sind, auch zu benutzerdefinierten Wörterbüchern hinzugefügt werden.
🛡 Sicherheit
- Die anfällige Bibliothek „jackson-core“ (die von der Grammatik-Engine verwendet wird) wurde auf Version 2.18.6 aktualisiert, um das Problem GHSA-72hv-8253-57qq zu beheben (Umgehung der Beschränkung der Zahlenlänge im asynchronen JSON-Parser, was zu einem potenziellen Denial-of-Service-Zustand führen könnte).
🐞 Fehlerbehebungen
- WProofreader JS-Kern: Hervorgehobene Vorschläge werden verschoben, wenn das Zoom-Plugin im CKEditor verwendet wird
- WProofreader JS-Kern: Uneinheitliches Verhalten der Tastaturnavigation im Dialogfeld des KI-Schreibassistenten in gemischten Umgebungen mit Links-nach-Rechts- und Rechts-nach-Links-Schreibrichtung
- Rechtschreibprüfung: Wörter, die mit typografischen Apostrophen geschrieben werden, werden im Katalanischen nicht als korrekt erkannt.
- Rechtschreibmodul: Aufteilungsregeln, die Zahlen enthalten, sind nicht zulässig
- Anwendungsserver: Die Funktion „Zulässige Regeln“ funktioniert nicht wie erwartet
- Anwendungsserver: Hunspell bricht ab, wenn das N-Gram-Modell nicht gefunden wird
- Styleguide: Die wichtigsten Regeln des Styleguides sind nicht lesbar
- Styleguide: Für Styleguide-Dateien werden relative Pfade verwendet